上一篇我们已经按照思路实现了基础功能,实现公式和图片的自动转换。
但是大家在使用的时候会发现,跑着跑着 就断掉了!报错了啊!丢失连接之类的。幸幸苦苦的抓了半天又得从头来,心累啊!
这就是网站的反爬虫在起作用了,一个IP访问次数过于频繁就先将这个IP加入黑名单,过一会儿再放出来。虽然不影响正常使用但是对于爬虫来说很致命啊!因为爬虫会报错退出啊!然后我们又得重来。
一般来说我们会遇到网站反爬虫策略下面几点:
- 后台对访问进行统计,如果单个userAgent访问超过阈值,予以封锁。(效果出奇的棒!不过误伤也超级大,一般站点不会使用,不过我们也考虑进去
- 限制IP访问频率,超过频率就断开连接。(这种方法解决办法就是,降低爬虫的速度在每个请求前面加上time.sleep;或者不停的更换代理IP,这样就绕过反爬虫机制啦!)
- 还有针对于cookies的 (这个解决办法更简单,一般网站不会用)
我们今天就来针对1、2两点来写个下载模块、别害怕真的很简单。
继续通过模仿来解决这个问题,继续在网上找大神写的博客https://cuiqingcai.com/3256.html「静觅丨崔庆才的个人博客」,看看人家是怎么做的。
首先我们修改User-Agent,这个参数是用来伪装成浏览器的,多写几个,就可以假装是不同浏览器在访问页面
搜索关键字 「User-Agent list」就可以得到了
1 |
|
这个思路非常清晰吧,就是每次使用的headers是随机得到的,这样第一个反爬虫手段就被我们解决了
首先一个问题是IP如何使用,假设我有一个IP1
2
3myip='111.222.333.444:5555'
proxy = {'http': myip}
start_html = requests.post(all_url,headers=headers,data=Para,proxies=proxy)
使用起来很简单,在requests里多加个参数proxies就行了,那我们的思路就清晰了,跟上面User-Agent一样,我们弄一个list,每次随机就OK了。
验证ip
首先是iP收集,同样通过搜索关键字「ip list」我找到了这个网站http://www.xicidaili.com/nt/, 先复制几个来用,结果发现,不能用,原来这些ip有很多是不能用的,我们需要把ip测试一下,选择其中能用的才行。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19import requests
ip_list=['119.28.182.147:3128', '183.30.197.243:9797', '119.122.31.117:9000', '119.29.6.127:3128', '14.153.55.64:3128',
'119.123.240.35:9797', '59.47.215.153:8080', '119.28.177.238:3128', '27.46.20.176:8888', '171.217.59.2:8888',
'117.65.32.96:41496', '175.171.179.84:53281', '139.129.166.68:3128', '112.67.172.123:9797', '27.44.164.201:9999',
'27.46.32.227:9797', '120.84.137.97:9000', '113.79.75.32:9797', '183.33.192.16:9797', '123.56.245.192:3128',
'113.73.17.110:808', '183.30.197.31:9797', '115.194.164.83:8118', '183.30.197.31:9797', '112.67.162.231:9797',
'116.226.222.125:9797', '111.230.32.95:3128', '218.93.174.188:6666', '27.46.23.89:8888', '121.231.150.201:6666']
ip_list_good=[]
for i in ip_list:
proxy = {'http': i}
print(proxy)
try:
requests.get('http://www.baidu.com/', proxies=proxy)
except:
print ('connect failed')
else:
print ('success')
ip_list_good.append(i)
print(ip_list_good)
思路是,使用ip去访问百度,或者你需要爬取的页面的网址,返回正确则ip用。(当时不知道如何爬取ip,我用的是截图然后用OneNote的识别功能把ip从图片提取出来,再用word替换掉一些不对的符号,得到的ip_list)
通过这个测试程序可以打印出有效的ip。
爬取ip
OK经过测试我们的思路完全没有问题,那么我们反爬虫的终极问题来了,怎么让程序自动获取ip?
我们首先想到的是把ip网址里的ip爬出来,然后验证,说干就干。
打开ip网址http://www.xicidaili.com/nt/,按下f12,选择你想要的ip。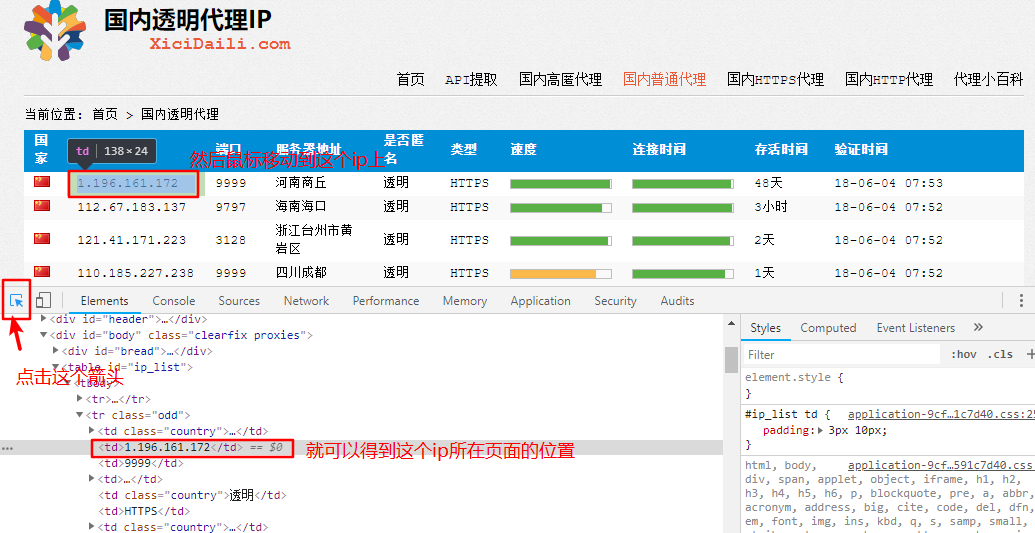
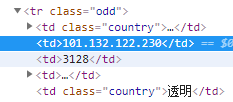
我们可以得到ip地址是在
1 | headers = {'User-Agent':"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36"} |
start_html.text就是这个页面所有的内容,类型是字符串,我们需要在这个字符串里找到我们想要的ip,发现没基础重要不,摸们现在面临的问题本质上是字符串的操作呀。
如何从网页中的标签提取内容,就要用到beautifulsoup这个库1
2
3
4
5
6
7
8
9import requests
from bs4 import BeautifulSoup
#https://www.cnblogs.com/hearzeus/p/5157016.html
headers = {'User-Agent':"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36"}
all_url = 'http://www.xicidaili.com/nt/' ##开始的URL地址
start_html = requests.get(all_url,headers=headers)
Soup = BeautifulSoup(start_html.text, 'lxml')
ip = Soup.find_all('td',class_=False)
print(ip)
我们分析页面可以发现,ip所在的地方有标签
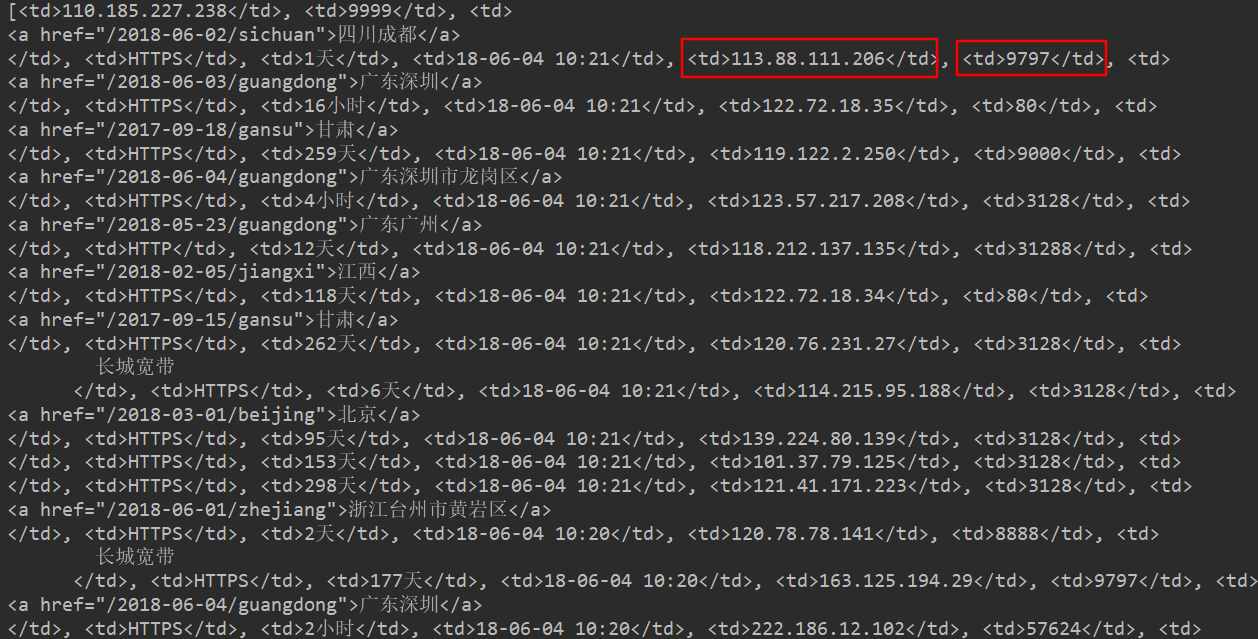
但是满足条件的还有很多,需要进一步筛选。我能想到的方法都是不停循环,反复筛选,有没有跟好的方法呢?
于是我又去搜索,发现大佬的爬虫用的是正则表达式,好像很牛,看看有没有现成可以用的。
https://blog.csdn.net/xysoul/article/details/79215650
http://www.cnblogs.com/zxin/archive/2013/01/26/2877765.html1
2
3
4
5
6import requests
import re
headers = {'User-Agent':"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36"}
all_url = 'http://www.xicidaili.com/nt/' ##开始的URL地址
start_html = requests.get(all_url,headers=headers)
print(re.findall(r"\b(?:[0-9]{1,3}\.){3}[0-9]{1,3}\b",start_html.text))
我去太牛了,ip全出来了,而且还是列表形式,但是没有办法提取端口呀,看看大神有没有写端口提取,好吧大神没写,没关系我们模仿一下。
re.findall(‘
这一句是找到
模仿一下得到
re.findall(r”
看看行不行。
1 | import requests |
我去真牛!正则表达式处理字符串的能力真是无敌呀,拿个小本本给正则表达式画上重点。
OK我们现在有了ip的列表,和端口的列表,需要要把它们合并起来,知道这题考什么吗?列表的操作。1
2
3IP_ip=re.findall(r"\b(?:[0-9]{1,3}\.){3}[0-9]{1,3}\b",start_html.text)
IP_port=re.findall(r"<td>([0-9]{2,5})</td>",start_html.text)
IP_all = list(map(lambda x: str(x[0])+':'+str(x[1]), zip(IP_ip, IP_port)))
OK现在我们就完成了最重要的获取一页ip地址了,我们只需要不断循环,获取所有页面的ip地址即可,最后一个知识点,构造所有的页面,
我们来分析一下
第一页的网址是http://www.xicidaili.com/nt/
第二页的网址是http://www.xicidaili.com/nt/2
我已经找到规律了,就是在基础网址上添加数字就行了。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16import requests ##导入requests
import os
from bs4 import BeautifulSoup ##导入bs4中的BeautifulSoup
import re
IP_all_old=[]
headers = {'User-Agent':"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36"}
for i in range(2,30) :
all_url = 'http://www.xicidaili.com/wt/'+str(i) ##开始的URL地址
start_html = requests.get(all_url,headers=headers)
IP_ip=re.findall(r"\b(?:[0-9]{1,3}\.){3}[0-9]{1,3}\b",start_html.text)
IP_port=re.findall(r"<td>([0-9]{2,5})</td>",start_html.text)
IP_all = list(map(lambda x: str(x[0])+':'+str(x[1]), zip(IP_ip, IP_port)))
IP_all=IP_all+IP_all_old
IP_all_old =IP_all
print(i)
print(IP_all)
通过这个程序可以提取2到29页的ip地址,把打印出来的ip复制到检测ip的程序里,然后把可以用ip复制到下载图片程序里的ip_list里,我们的公式转换图片就可以无忧无虑的工作了。
改进后的公式转图片程序
1 | import requests ##导入requests |
把之前的程序拆成了两部分,一部分获取图片的下载链接,另一部负责下载程序,这样调试起来方便一些。
通过不断的改进我们把其实已经把常用的爬虫知识点都给过了一遍,现在是不是对爬虫有更直观的了解了呢?你现在应该已经可以像我一样模仿着大神的步伐来实现自己的功能了,所以你的爬虫开始工作了吗?
关注微信公众号,回复【公式图片】即可获取源码哦。


