我写的文章里通常有很多公式,这些公式是用LaTeX语法写的,
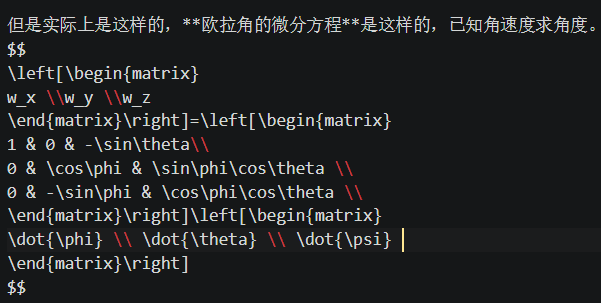
经过浏览器的渲染就可以显示为正确的公式,但是公众号和有些网站对公式的支持很差,无法显示正确排版的公式。如果需要把文章发到不同的网站,往往需要单独调整格式。
所以通常的做法是,把公式转换成图片,使用url的形式显示图片,然后再发到公众号,保证公式的正确。
于是我想,能不能写个工具,把文章里的公式都转成图片,并且直接生成一篇转换后新的文章。
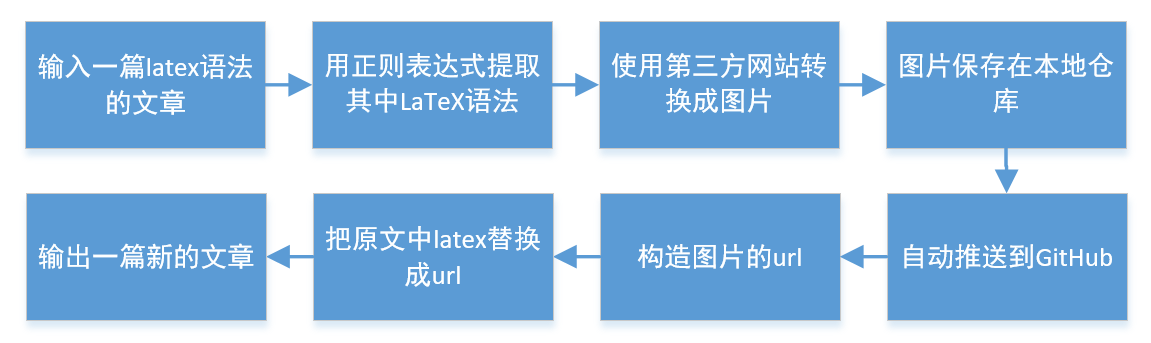
我把这个目标分解成了几个步骤:
1.输入原始文章,查找其中的LaTeX
2.提取文章中的latex公式,转换成图片
3.把图片下载到我的git本地仓库
4.git上传到github
5.生成图片的url
6.用url替换latex公式,生成新的文章
输入原始文章,查找其中的LaTeX语法
这一步主要用到的知识点:
python如何提取文件中的中文
用正则表达式在字符串中提取自己想要的部分1
2
3
4
5
6
7
8source_article_path='D:\\OneDrive - business\\Markdown\\自动生成的新文章'
source_article='2018-11-07[飞控]姿态误差(一)-欧拉角做差.md'
with open(source_article_path+'\\'+source_article,'rb') as f:
#以utf-8格式提取中文,避免出现乱码
article=f.read().decode('utf-8')
comment = re.compile('\$\$.*?\$\$', re.DOTALL)
a=comment.findall(article,re.S)
print('提取'+source_article+'中的公式')
latex公式转换成图片,并下载
借用第三方网址,把latex语法转换成图片
这一步用到一点爬虫的网络请求
以及如何下载图片1
2
3
4
5
6
7
8
9
10for i in range(len(a)):
formula=a[i][2:-2]
#formula 就是latex语法 的字符串
img = session.get('http://latex.codecogs.com/gif.latex?' + formula)
#下载转换好的图片
f = open(str(i)+'.png', 'ab')
f.write(img.content) ##多媒体文件要是用conctent哦!
f.close()
#暂停10s,太快会被封IP
time.sleep(10)
构造图片url格式
因为GitHub不会自己返回图片的url,所以需要根据自己的仓库名和图片明自己构造url。
这一步图片还没上传,只是先构造url,用到的是字符串操作的基础知识。1
2
3
4img_url='https://raw.githubusercontent.com/ZingHD/Markdown_picture/master/'+article_title+'/'+str(i)+'.png'
img_urls.append(img_url)
print('正在生成图片 进度'+str( ((i+1)/len(a))*100) + '%')
print(img_urls[i])
git上传到github
使用python的git库,自动添加修改,并上传到自己的GitHub1
2
3
4
5
6repo = git.Repo(r'D:\Markdown_picture')
git = repo.git
git.add(article_title) # git add test1.txt
git.commit('-m', 'add'+article_title+time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())) # git commit -m 'this is a test'
remote = repo.remote()
remote.push()
用url替换latex公式,生成新的文章
1 | print('在目录'+'source_article_path'+'中用url替换文章里的公式') |
到此就完成了我需要的全部功能。

可继续改进的地方:
1.判断是否有重复文件夹,重复图片,有就跳过
2.调用次数过多会被封IP
收获,在没有分解任务之前觉得非常难,但是通过任务的合理划分,把任务分成一个一个可以执行的小步骤,你会发现每个步骤都是可以明确行动,并且涉及的知识也是非常初级的。就像给自己制定计划一样,如果把计划拆分到每一个可以执行的步骤,你会发现你离你的目标越来越近。
生命在于折腾,关注微信公众号,回复【url】可以获得img2url的源码哦。


